

Jong Hoon

When I first started exploring the world of AI accelerators, I found it helpful to read a set of well-written papers and project reports. They introduced me to key ideas such as roofline models, blocking strategies, dataflow mapping, sparsity, mixed precision, and real chip designs.
This list is organized by publication date, with short notes on why each work is useful. I hope it serves as a helpful guide for anyone just beginning to learn how AI accelerators work.
2009 — The Roofline Model
-
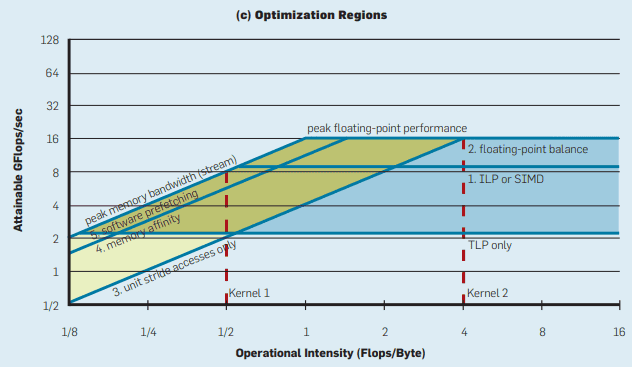
Berkeley Roofline: An Insightful Visual Performance Model
A classic performance model that shows the balance between memory bandwidth and compute capacity. Very approachable for visualizing bottlenecks.
2016 — Early CNN Accelerators and ISA
-
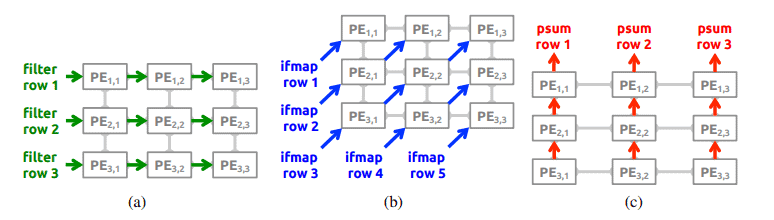
MIT Eyeriss (ISCA ’16)
Introduces the Row-Stationary dataflow, a gentle entry point into how data movement dominates energy use.
-
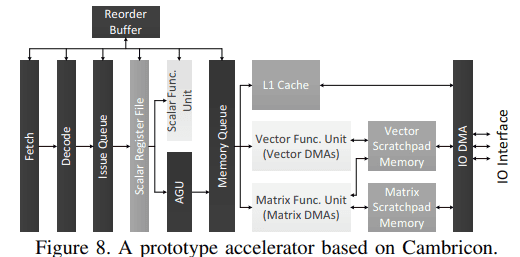
Cambricon ISA (ISCA ’16)
A domain-specific instruction set for neural networks, showing how hardware/software co-design starts at the ISA level.
-
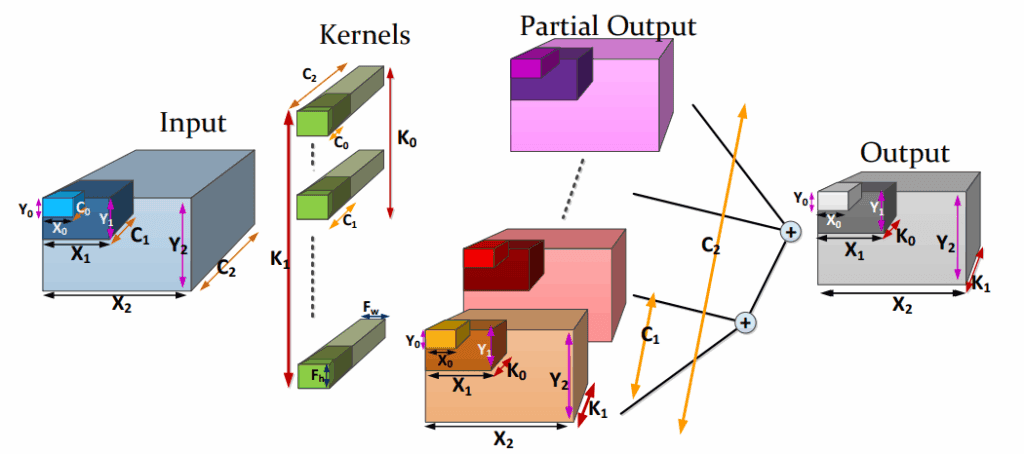
A Systematic Approach to Blocking CNNs (2016, arXiv)
Explains how simple loop blocking can drastically reduce DRAM traffic. Clear diagrams make it easy to follow.
-
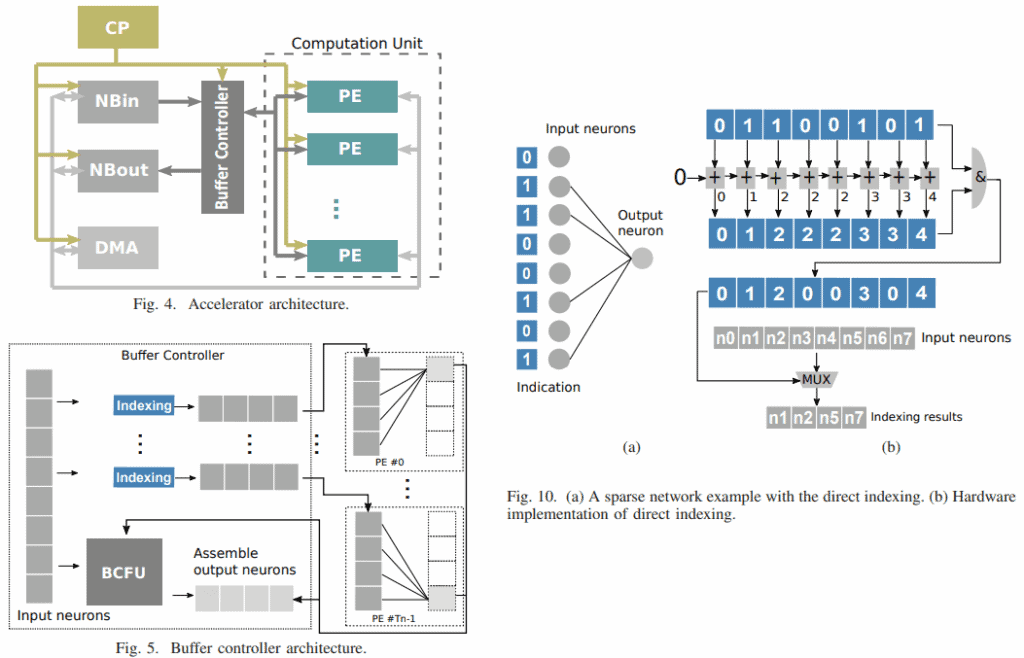
Cambricon-X (MICRO ’16)
Shows how sparsity can be used to cut down unnecessary operations and memory use.
2017 — Google’s TPU
-
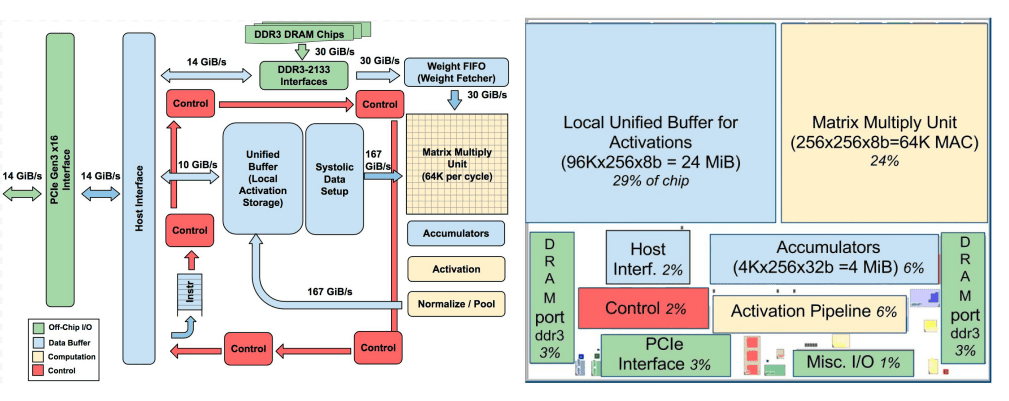
In-Datacenter Performance Analysis of a TPU (ISCA ’17)
A real-world example of how Google built an inference ASIC. The paper is accessible and provides a concrete view of performance and memory limits.
2018 — Beyond Dense CNNs
-
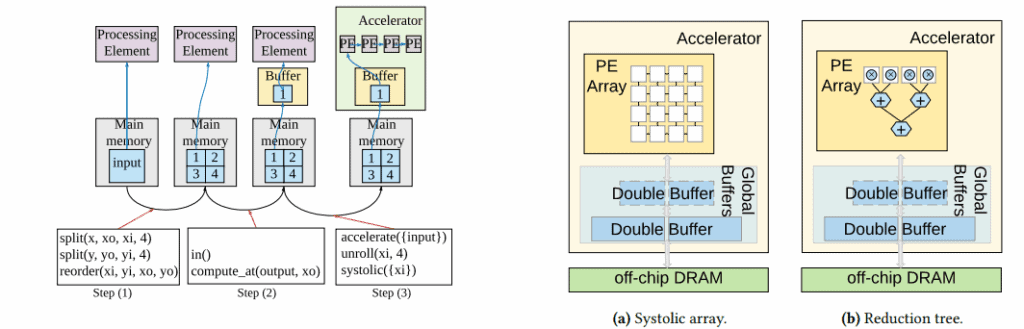
Interstellar (ASPLOS ’20, preprint ’18)
Uses Halide’s scheduling language to describe different accelerator dataflows in a unified way. Helpful for beginners because it shows many designs side by side.
-
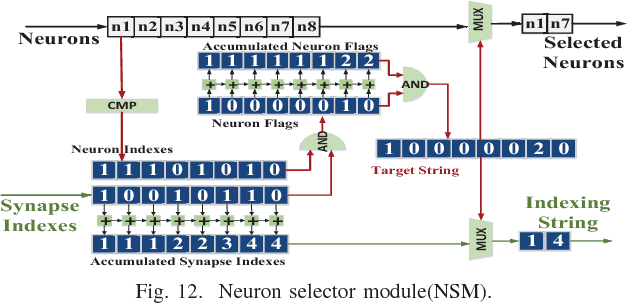
Cambricon-S (MICRO ’18)
Tackles the irregularity of sparse networks with a mix of software and hardware ideas.
2019 — Modeling Dataflow and Reuse
-
MAESTRO (MICRO ’19)
A tool that helps quantify reuse, buffer sizes, and bandwidth. A friendly starting point for understanding the notion of dataflow and mapping strategies.

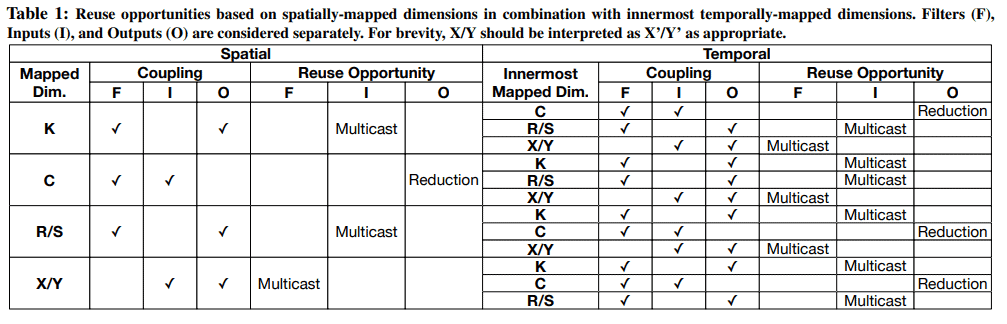
2021 — Mixed Precision and Mobile NPUs
-
Rethinking Floating Point Overheads (MLSys ’21)
Explains how mixed precision can be supported efficiently. Good for learning why hardware doesn’t always stick to one number format.
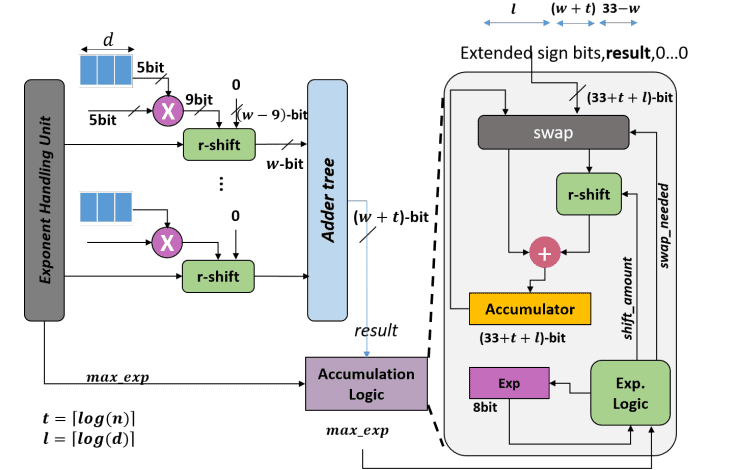
-
Samsung Reconfigurable NPU (ISCA ’21)
A commercial example: how Samsung built a flexible NPU for mobile devices.
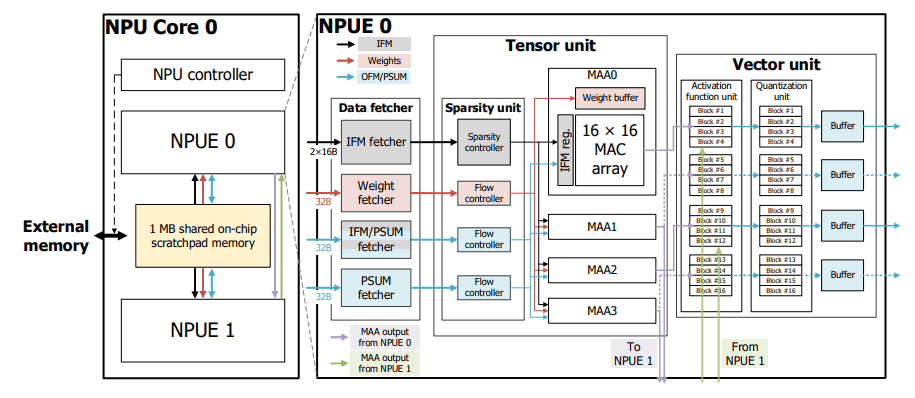
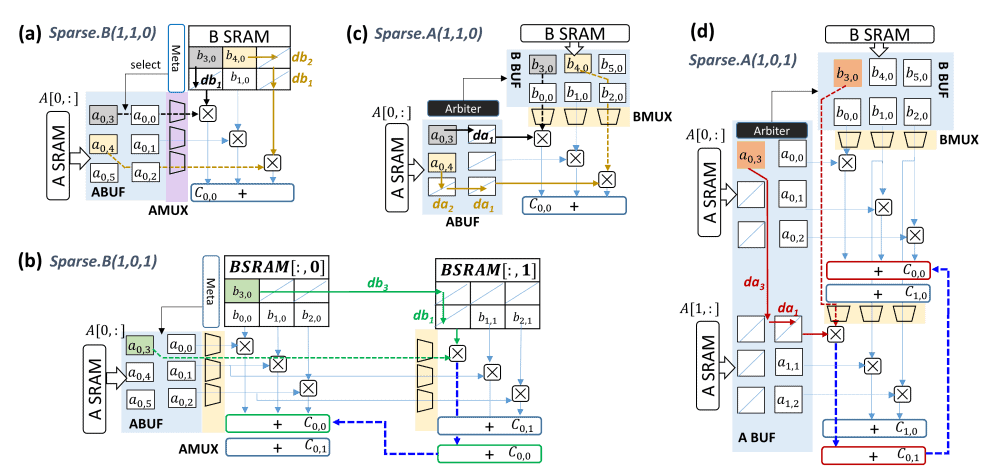
-
Griffin (HPCA ’22, preprint ’21)
A clear explanation of how to handle both sparse and dense models efficiently.
2024 — Meta MTIA
-
Meta MTIA v2 (2024 blog)
Meta’s own custom accelerator for recommendation systems. The blog post format makes it approachable without too much jargon.
2025 — Extending Rooflines for ML Accelerators
-
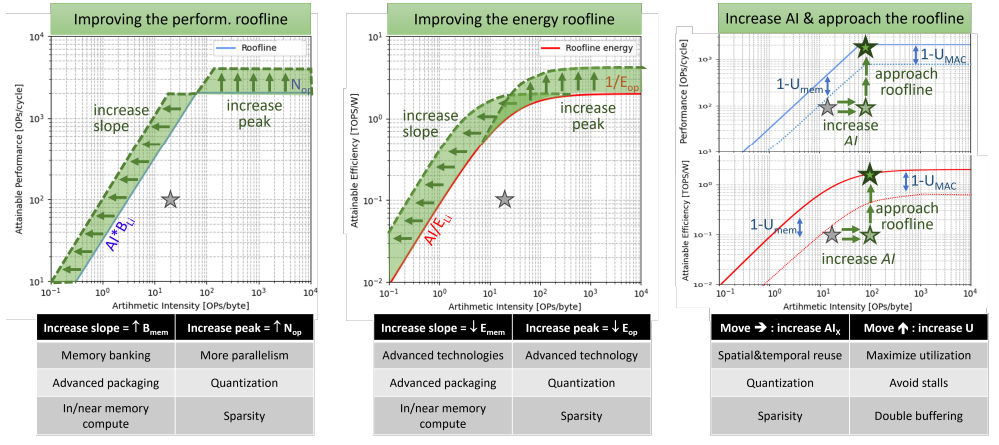
How to Keep Pushing ML Accelerator Performance? Know Your Rooflines! (2025)
An updated look at the roofline model, now applied to modern ML accelerators, covering mixed precision and new memory technologies.
Closing Thoughts
This list isn’t meant to be a set of “must-reads,” but rather a collection of papers I personally enjoyed while building my own understanding of AI accelerators. It started as my own reading list, and over time I found that these works gave me both the theory and the real-world perspective—from the early Roofline model and dataflow representations all the way to modern ASICs like TPU, Samsung’s NPU, and Meta’s MTIA.
Looking back, I think these papers made it much easier for me to take my first steps with confidence. I hope that by sharing them, they can also serve as a gentle guide for anyone just beginning their own journey into the world of AI accelerators.
What a wonderful post! Thank you for organizing it so neatly. It helps a lot.
I’m so glad you found it helpful—thank you for your kind words!