Jong Hoon

Why “Computer Architecture: A Quantitative Approach”?
When I first started studying computer architecture, I relied on textbooks like Computer Organization and Design (Patterson & Hennessy) and Digital Design and Computer Architecture (Harris & Harris) to build a solid foundation in instruction-set architecture and microprocessor basics. While these books were incredibly helpful for understanding the fundamentals, they fell short in covering state-of-the-art technologies and the broader system-level context.
Reading Computer Architecture: A Quantitative Approach helped bridge that gap. Through this book, I was able to explore not only architecture and microarchitecture, but also how they interact with other areas of computer science—especially compilers, applications, operating systems, networks, and memory subsystems.
This blog post series is my attempt to share my notes and insights as I work through the book. I hope it helps others deepen their understanding of modern computer architecture and its place in the larger computing stack.
Chapter 1: Fundamentals of Quantitative Design and Analysis
In the remainder of this post, I summarize Chapter 1—Fundamentals of Quantitative Design and Analysis—from Computer Architecture: A Quantitative Approach by Patterson and Hennessy.
Introduction
The landscape of computer architecture has undergone major transformations, especially driven by changes in the marketplace and advancements in technology.
1. Two Significant Changes in the Computer Marketplace
- The virtual elimination of assembly language programming has shifted focus toward high-level programming languages, improving productivity and portability.
- The rise of standardized, vendor-independent operating systems, such as UNIX and Linux, created a more consistent software environment across hardware platforms.
2. Emergence of Simpler Instruction Set Architectures
A new class of architectures with simplified instruction sets—RISC (Reduced Instruction Set Computer)—emerged, enabling better performance and easier implementation. Two key techniques contributed to this performance gain:
- Instruction-level parallelism (ILP), where compilers and hardware work together to execute multiple instructions simultaneously.
- Use of caches, reducing memory access latency.
This shift challenged the dominance of traditional CISC architectures like 80×86. Meanwhile, ARM architectures grew in popularity and have become dominant, especially in mobile and embedded devices.
3. The Fourfold Impact of Marketplace Growth
The rapid expansion of the computer market led to:
- Enhanced capabilities for personal users, making powerful computing accessible.
- New classes of computing devices, including:
- Personal computers
- Workstations
- Smartphones
- Tablets
- Warehouse-scale computers (WSCs)
- Supercomputers
- A hardware renaissance fueled by Moore’s Law, which drove exponential improvements in performance and integration.
- Rapid software development, characterized by:
- Performance-oriented languages: C, C++
- Managed languages: Java, Scala
- Scripting languages: JavaScript, Python
- Web and application frameworks: AngularJS, Django
- Just-in-time compilers and trace-based compiling
- Emergence of Software as a Service (SaaS) and cloud platforms
- A surge in application domains: speech, image, and video processing
- Example: Google Translate running on WSCs
4. The End of the Hardware Renaissance
The slowdown of traditional hardware scaling marked the end of this renaissance:
- Dennard Scaling, which once kept power density constant as transistors shrank, no longer held.
- Moore’s Law—the doubling of transistor counts every two years—began to face physical and economic limits.
To sustain performance growth, architects began using multiple cores per chip, introducing various forms of parallelism:
- Instruction-level parallelism (ILP) – compiler and hardware cooperation without programmer involvement
- Data-level parallelism (DLP)
- Thread-level parallelism (TLP)
- Request-level parallelism (RLP) – especially relevant in WSCs
However, Amdahl’s Law imposes practical limits on how much benefit can be gained from adding more cores. As a result, the field has come to a key realization:
“The only path left to improve energy-performance-cost is specialization.”
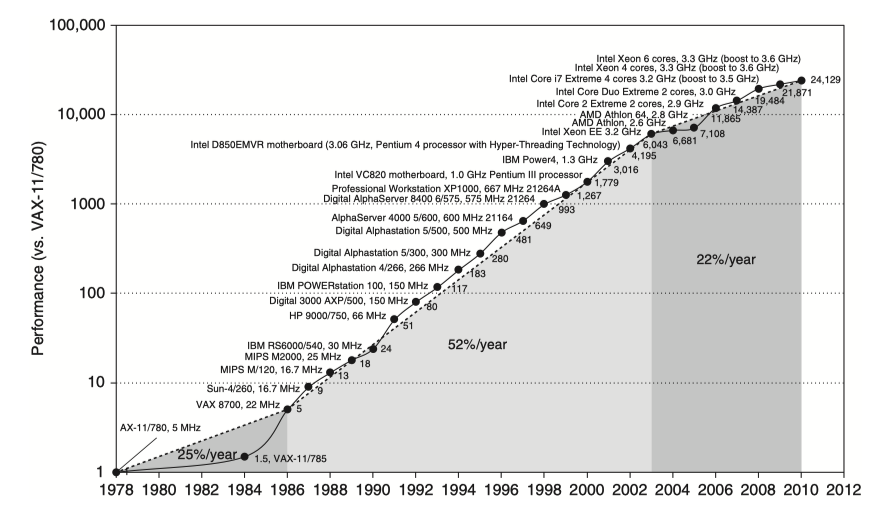
5. Growth in Processor Performance
Since the late 1970s, processor performance has grown dramatically, initially driven by increasing clock rates and ILP, and more recently by parallelism and architectural specialization.
Classes of Computers
Modern computing devices are categorized into several classes based on their performance goals, usage contexts, and architectural characteristics.
1. Internet of Things (IoT) and Embedded Computers
These are low-power devices embedded in everyday appliances and industrial systems. Cost and energy efficiency are critical.
-
8/32-bit processors are used for low-cost, simple devices such as microwaves and washing machines.
-
64-bit processors are used in high-end embedded systems like modern automobiles and network switches.
2. Personal Mobile Devices (PMDs)
Personal devices like smartphones and tablets prioritize responsiveness and energy efficiency.
-
Must support real-time performance for user interaction.
-
Focus on predictability, not just raw performance.
-
Emphasize minimal memory footprint and low energy consumption.
3. Desktop Computing
Desktop systems are designed for a balance of interactivity and computational workload.
-
Benchmarks are often based on web-centric and interactive applications.
-
Performance is tuned for user responsiveness in common productivity and development tasks.
4. Servers
Servers are optimized for throughput and scalability, serving multiple users concurrently.
-
Availability: Must operate 24/7 without interruption.
-
Scalability: Capable of expanding CPU, memory, storage, and I/O as needed.
-
Prioritize efficient throughput over individual responsiveness.
5. Clusters and Warehouse-Scale Computers (WSCs)
Large-scale computing systems that power cloud services and high-end computations.
-
Growth driven by Software-as-a-Service (SaaS) demand.
Clusters:
-
Made up of interconnected desktop computers or servers.
-
Each node has its own OS and communicates via a network.
-
Acts as a single virtual machine.
Warehouse-Scale Computers (WSCs):
-
Represent the largest clusters, like those used by cloud providers.
-
Built using inexpensive, redundant components rather than traditional enterprise-grade servers.
-
Optimize for price-performance and power efficiency.
-
Designed for availability during demand spikes, e.g., holiday shopping season.
Supercomputers:
-
Extremely high-end machines focused on floating-point performance.
-
Used for large, batch-oriented, communication-intensive programs.
-
Typically very expensive and specialized.
6. Classes of Parallelism and Parallel Architectures
Modern applications and systems exploit different types of parallelism to achieve performance gains.
Application-level parallelism:
-
Data-level parallelism (DLP): Performing the same operation on multiple data elements.
-
Task-level parallelism (TLP): Performing different operations in parallel.
Hardware-level parallelism:
-
Instruction-level parallelism (ILP):
-
Achieved via pipelining and speculative execution.
-
Does not require software-level parallel code.
-
-
Vector architectures, GPUs, multimedia instruction sets:
-
Enable DLP by applying a single instruction across multiple data points.
-
-
Thread-level parallelism (TLP):
-
Multiple threads running in a tightly coupled hardware model.
-
Often paired with DLP.
-
-
Request-level parallelism (RLP):
-
Exploits parallelism between loosely coupled, independent requests.
-
Flynn’s Taxonomy (1966):
-
SISD (Single Instruction, Single Data): Traditional scalar pipelines with ILP.
-
SIMD (Single Instruction, Multiple Data): Used in vector processors and GPUs.
-
MISD (Multiple Instruction, Single Data): Rare, but seen in systolic arrays.
-
MIMD (Multiple Instruction, Multiple Data): Common in multicore and multithreaded systems, combining DLP, TLP, and RLP.
Defining Computer Architecture
Computer architecture can be broadly divided into instruction set architecture (ISA) and its implementation, which includes microarchitecture and hardware design.
1. Instruction Set Architecture (ISA): The Myopic View
ISA is the interface between software and hardware, consisting of the actual instructions visible to the programmer.
-
Popular ISAs include x86, ARMv8, and RISC-V.
-
RISC-V stands out for:
-
A large register file
-
Pipeline-friendly instructions
-
A minimal yet complete set of operations
-
Key Aspects of ISA Design:
-
Classes of ISAs
-
Most are general-purpose register architectures.
-
Register-memory ISAs: e.g., x86
-
Load-store ISAs: e.g., ARMv8, RISC-V
-
-
-
Memory Addressing
-
Typically uses byte-addressable memory
-
Some architectures require aligned access for performance or correctness
-
-
Addressing Modes
-
Define how memory operands are specified
-
RISC-V uses: Register, Immediate, Displacement
-
-
Operand Types and Sizes
-
Includes: ASCII, Unicode, Integers, Floating-point (FP32, FP64), etc.
-
-
Operations
-
Categories: Data transfer, Arithmetic/Logic, Control, Floating-point
-
-
Control Flow Instructions
-
Includes: Conditional/unconditional branches, jumps, procedure calls/returns
-
-
Instruction Encoding
-
Fixed-length (RISC-V, ARM) vs Variable-length (x86)
-
RISC-V also specifies calling conventions and register usage, with details provided in Appendix A.
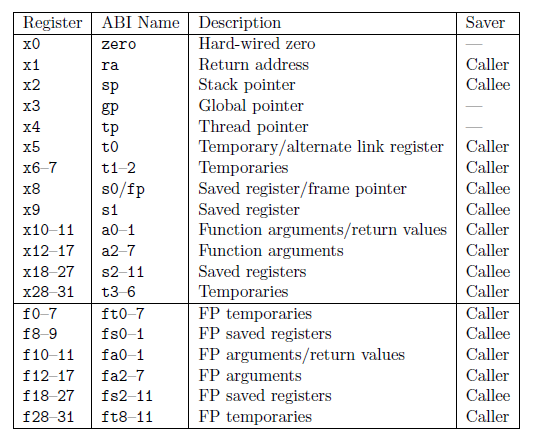
2. Genuine Computer Architecture: Beyond the ISA
True computer architecture includes not just the ISA, but also how the system is implemented:
-
Implementation = Microarchitecture (organization) + Hardware
-
Architecture = ISA + Microarchitecture + Hardware
Trends in Technology and Architecture
Modern computer architecture is shaped by several evolving trends:
-
Technology
-
Advances in IC logic, DRAM, Flash, Disk, and Networking
-
-
Performance
-
Stalling of clock speed gains; shift toward parallelism and specialization
-
-
Scaling Limitations
-
Transistors scale better than wires
-
Leads to “dark silicon” where parts of the chip must be powered down
-
-
Domain-Specific Processors
-
Emergence of specialized hardware to meet performance and energy goals
-
-
Power and Energy
-
Efficiency is a first-class design constraint in modern architectures
-
-
Cost Considerations
-
Includes time-to-market, manufacturing cost, operational cost, and volume-driven commoditization
-

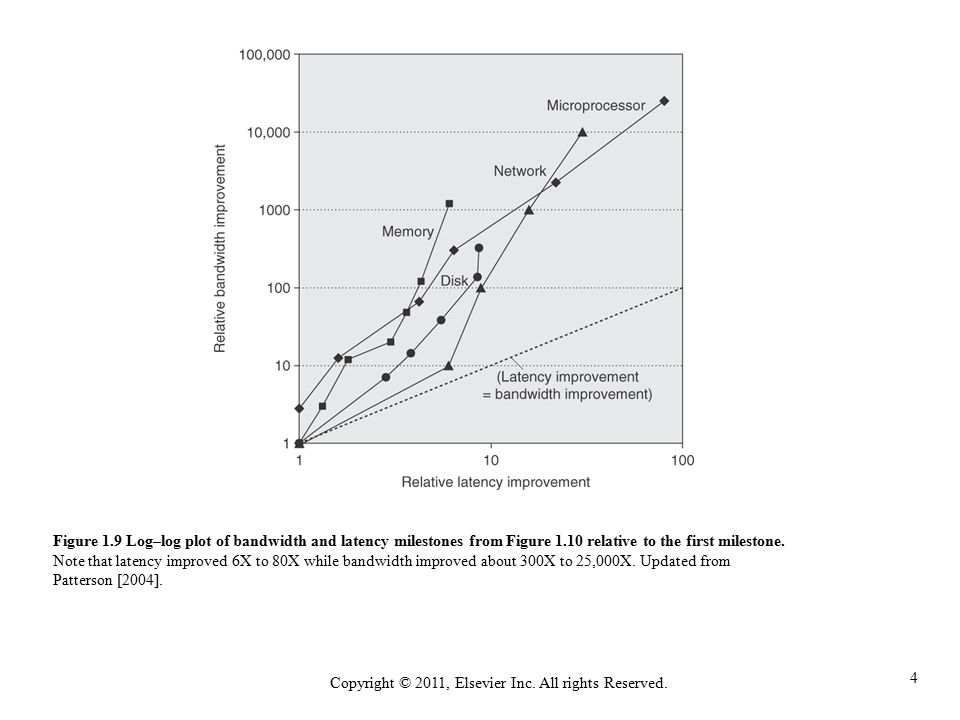
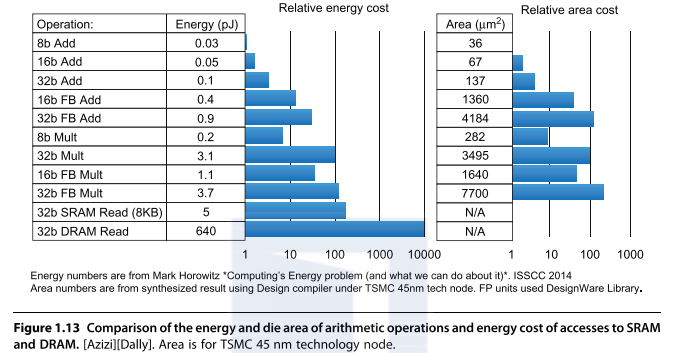
Dependability
Dependability concerns whether a system behaves correctly and reliably.
-
Failures in lower levels (e.g., hardware) can propagate up to affect software and application behavior.
-
Important concepts include:
-
Service-Level Agreements (SLAs) and Service-Level Objectives (SLOs)
-
Module Reliability:
-
MTTF (Mean Time To Failure)
-
MTTR (Mean Time To Repair)
-
-
Availability Formula:
-
Availability = MTTF / (MTTF + MTTR)
-
-
Measuring, Reporting, and Summarizing Performance
Performance evaluation is crucial in computer design and requires standardized benchmarks and metrics.
-
Types of Benchmarks:
-
Kernels: Small code segments from real applications
-
Toy programs: Simple but illustrative
-
Synthetic benchmarks: Artificial programs designed to stress specific components
-
Benchmark suites: Collections of representative workloads (e.g., SPEC)
-
-
Processor Performance Metrics:
-
CPI: Clock cycles per instruction
-
IPC: Instructions per clock (inverse of CPI)
-
Quantitative Principles of Computer Design
Several key principles guide performance-efficient computer design:
-
Take Advantage of Parallelism
-
At instruction, data, thread, and request levels
-
-
Principle of Locality
-
Exploiting temporal and spatial locality improves cache and memory performance
-
-
Focus on the Common Case
-
Optimize for frequently executed paths or scenarios
-
-
Amdahl’s Law
-
Highlights the limits of parallel speedup when portions of a task are serial
-