1. The Berkeley Out-of-Order Machine (BOOM)
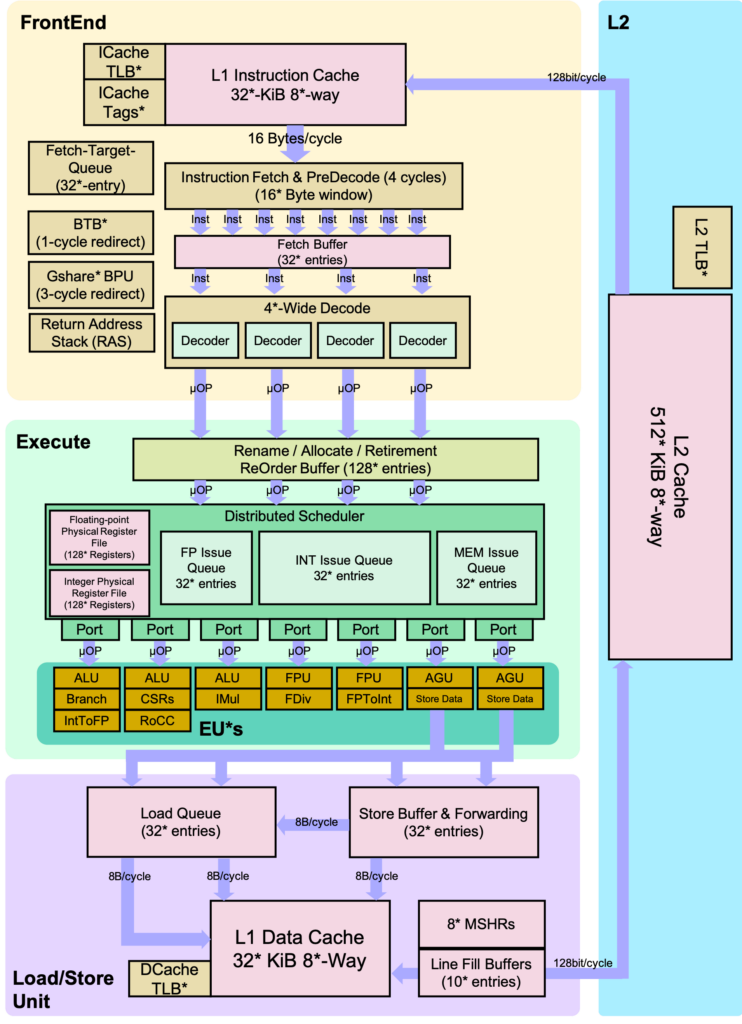
Fig. 1 Detailed BOOM Pipeline. *’s denote where the core can be configured.
- Inspiration: The BOOM (Berkeley Out-of-Order Machine) is inspired by the MIPS R10000 [2] and Alpha 21264 [3] out-of-order processors.
- Unified Physical Register File: BOOM employs “explicit register renaming,” similar to its inspirations.
- RISC-V ISA: BOOM implements the open-source RISC-V instruction set architecture.
- Chisel Construction: It uses the Chisel hardware construction language to create a generator for the core, making it more flexible than a single RTL design.
- Family of Designs: BOOM represents a family of out-of-order cores rather than a single instance.
- SoC Integration: BOOM integrates with the Rocket Chip SoC generator to reuse micro-architecture structures like TLBs and PTWs when building a system-on-chip (SoC).
2. The BOOM Pipeline
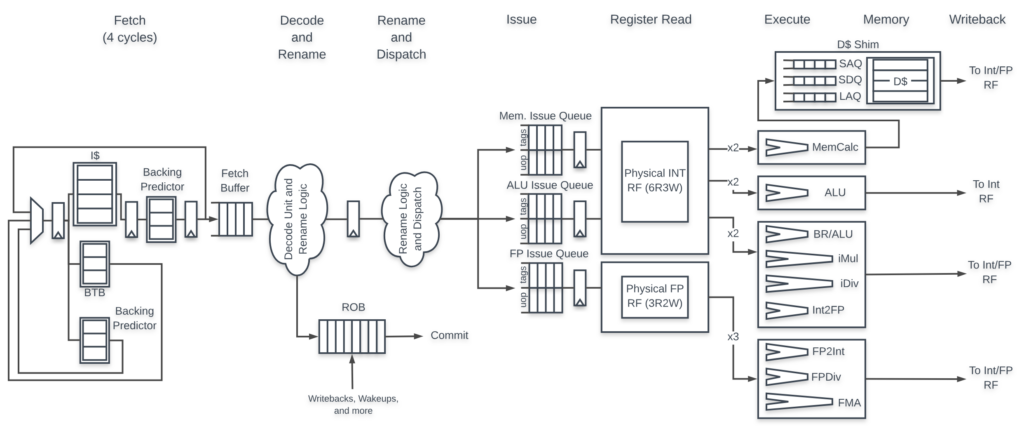
The BOOM (Berkeley Out-of-Order Machine) pipeline implements an advanced out-of-order execution mechanism for the RISC-V ISA. BOOM consists of ten conceptual stages: Fetch, Decode, Register Rename, Dispatch, Issue, Register Read, Execute, Memory, Writeback and Commit. It is structured into seven primary stages that optimize performance, resource usage, and speculative execution capabilities.
Pipeline Stages
- Fetch:
- Instructions are fetched from memory and stored in the Fetch Buffer [5].
- Fetch Buffer: Buffer that holds Fetch Packets that are sent to the Back-end.
- Fetch Packet: A bundle returned by the Front-end which contains some set of consecutive instructions with a mask denoting which instructions are valid, amongst other meta-data related to instruction fetch and branch prediction. The Fetch PC will point to the first valid instruction in the Fetch Packet, as it is the PC used by the Front End to fetch the Fetch Packet.
- Fetch PC: The PC corresponding to the head of a Fetch Packet instruction group.
- Branch prediction is applied to redirect instruction flow when necessary.
- Instructions are fetched from memory and stored in the Fetch Buffer [5].
- Decode/Rename:
- Instructions are decoded into Micro-Operations (uOps). [6]
- Micro-Op (UOP): Element sent throughout the pipeline holding information about the type of Micro-Op, its PC, pointers to the FTQ, ROB, LDQ, STQs, and more.
- Logical registers are renamed into physical registers for handling out-of-order execution.
- Instructions are decoded into Micro-Operations (uOps). [6]
- Rename/Dispatch:
- uOps are dispatched into the Issue Queue, awaiting execution.
- Issue/Register Read:
- uOps are issued once operands are available.
- Operands are retrieved from the Physical Register File or the Bypass Network.
- Execute:
- Functional units perform operations such as arithmetic, logic, and address calculations.
- Memory:
- Memory operations (loads/stores) are handled using dedicated queues:
- Load Address Queue (LAQ), Store Address Queue (SAQ), and Store Data Queue (SDQ).
- Writeback:
- Results are written back to the Physical Register File.
Key Features
- Commit:
- Not counted as a part of the pipeline since commit occurs asynchronously Reorder buffer (ROB) tracks the status of each instruction in the pipeline and commits instructions at the head of the buffer when ready.
- For stores, ROB signals the Store Address Queue (SAQ) or Store Data Queue (SDQ) to write data to memory.
- Branch Prediction:
- Each instruction is accompanied by a Branch Tag for speculative execution.
- Mis-predicted branches trigger pipeline flushing and state restoration.
- When a branch instructions passes through Rename, copies of the Register Rename Table and the Free List are made. On a mispredict, the saved processor state is restored.
- Unified Physical Register File:
- A single register file stores both speculative and committed states, supporting out-of-order execution.
- Floating Point Support:
- Includes specialized floating-point units, sourced from Rocket and Berkeley Hardfloat libraries, with consistent latency management.
- Load/Store Unit:
- Manages memory operations with queues to ensure coherence and correctness.
- Scalability
- The BOOM pipeline is highly parameterized, making it adaptable for a wide range of performance and resource requirements.
3. RISC-V ISA in BOOM
- BOOM implements the RV64GC variant, which includes:
- Base ISA and extensions: IMAFDC (integer, multiply/divide, atomic, single-precision, and double-precision floating point).
- Privileged specification support for system-level functionality.
Advantages of RISCV-V ISA for High-Performance Designs
- Relaxed Memory Model:
- Simplifies the Load/Store Unit (LSU) by avoiding the need for:
- Loads snooping other loads.
- Coherence traffic snooping in the LSU (as required by sequential consistency).
- Floating Point Exception Flags:
- FP status register does not require renaming.
- FP instructions do not throw exceptions.
- No Integer Side-Effects:
- Integer ALU operations only write to the destination register, avoiding additional condition state renaming.
- No
cmovor Predication:- Avoids added complexity in out-of-order pipelines by:
- Simplifying branch predictor design.
- Preventing the need for an additional read port for integer operations.
- Explicit Register Specifiers:
- Instructions like JAL require explicit register declarations, streamlining:
- Rename table logic.
- Instruction decoding paths.
- Consistent Register Placement:
- Registers (
rs1,rs2,rs3,rd) are always in the same location, allowing: - Parallel decoding and renaming.
- Registers (
4. Rocket Chip SoC Generator
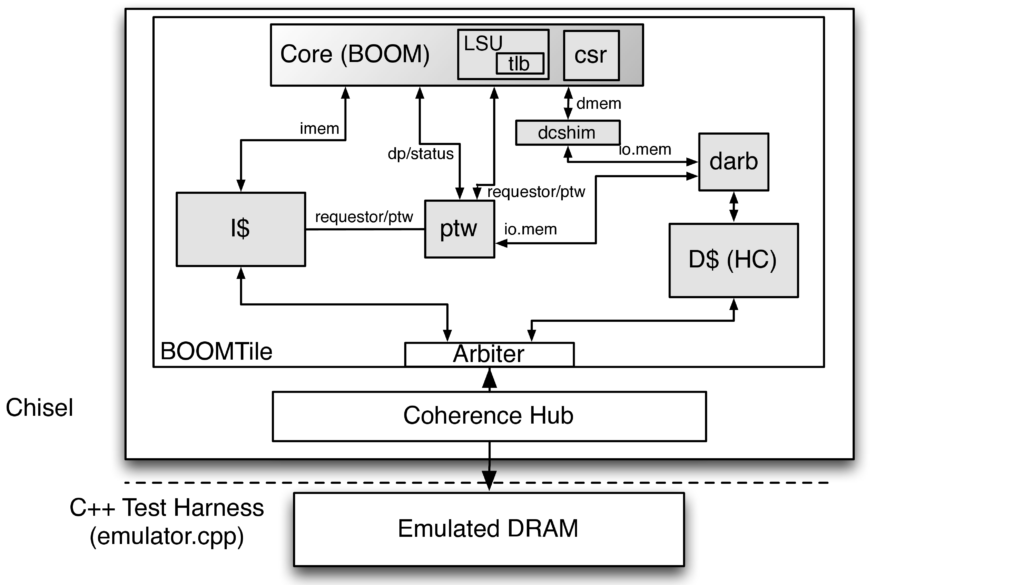
- BOOM serves as a core within a larger System-on-Chip (SoC) infrastructure.
- It leverages the Rocket Chip SoC generator, an open-source tool that:
- Supports a variety of SoC designs, including:
- Cache-coherent multi-tile systems.
- Cores with or without accelerators.
- Chips with or without a last-level shared cache.
- By default, includes a 5-stage in-order core called Rocket.
- Supports a variety of SoC designs, including:
- BOOM uses Rocket Chip to instantiate its core/tile complex:
- A tile includes:
- The core itself.
- L1 instruction and data caches (L1D/I$).
- A page table walker (PTW).
- A tile includes:
Rocket Core as a “Processor Component Library”
- The Rocket core acts as a modular library of processor components, which BOOM utilizes for:
- Functional units.
- Caches.
- Translation Lookaside Buffers (TLBs).
- Page Table Walker (PTW).
- BOOM integrates these components for its out-of-order processor design.
References
[1] “The Berkeley Out-of-Order Machine (BOOM)” chapter is summarized from The Berkeley Out-of-Order Machine (BOOM)
[2] Yeager, Kenneth C. “The MIPS R10000 superscalar microprocessor.” IEEE micro 16.2 (1996): 28-41.
[3] Kessler, Richard E. “The alpha 21264 microprocessor.” IEEE micro 19.2 (1999): 24-36.
[4]”The BOOM Pipeline” is summarized from The BOOM Pipeline
[5] While the Fetch Buffer is N-entries deep, it can instantly read out the first instruction on the front of the FIFO. Put another way, instructions don’t need to spend N cycles moving their way through the Fetch Buffer if there are no instructions in front of them.
[6] Because RISC-V is a RISC ISA, currently all instructions generate only a single Micro-Op (UOP). More details on how store UOPs are handled can be found in The Memory System and the Data-cache Shim.
[7] “RISC-V ISA in BOOM” chapter is summarized from The RISC-V ISA
[8] “Rocket Chip SoC Generator” chapter is summarized from Rocket Chip SoC Generator